Ich bin gerade dabei, die Kernfunktionen der Solaranzeige, nämlich das Auslesen von Geräten und Schreiben in Influx, mit Java neu zu programmieren.
Dabei habe ich versucht, ein Konzept zu erarbeiten, welches die Geräte nicht mehr hart ausprogrammiert, sondern eher textuell beschreibt. Damit wären Anpassungen oder Neuaufnahmen zukünftig um einiges leichter. Klar muss man immer noch bei vielen Geräten Anpassungen vornehmen, aber die halten sich doch sehr in Grenzen.
Im Kern gibt es drei wichtige Objekte im Konzept:
| Feld | Bedeutung |
|---|---|
| DeviceField | Technische Beschreibung des auszulesenden Feldes |
| ResultField | Tatsächlich ausgelesener Wert zur Laufzeit mit Status (OK, ERROR) |
| TableField | Beschreibung der zu exportierenden Tabellenspalte |
„DeviceFields“ werden in der ersten Ausbaustufe als json Dateien hinterlegt und beinhalten die technischen Angaben zu den einzelnen Gerätefeldern. (Später kann die Verwaltung in einer Datenbank erfolgen). Das könnte in Excel zum Beispiel so aussehen:

Diese werden beim ersten Start für das jeweilige Gerät eingelesen und im Speicher vorgehalten.
Falls das Modbus Protokoll eingesetzt wird, werden zusammenhängende Felder noch „verdichtet“, damit größere Pakete en Block gelesen werden können. Das beschleunigt das Auslesen der Felder.
Im nächsten Schritt werden die Daten von dem Gerät ausgelesen und in einer Menge von „ResultFields“ vorgehalten.
Diese haben den Namen aus dem DeviceField, einen Auslesestatus und den Wert je nach Datentyp.
Ist ein Faktor hinterlegt, wird dieser gleich mitberücksichtigt und der Wert umgerechnet.
Würde als im obigen Beispiel im Feld PV_Leistung der Wert 1200 ausgelesen, würde dieser mit 0.1 multipliziert und hinterlegt werden (also 120).
Nun sind die Daten ausgelesen aber wie werden diese exportiert?
Dafür gibt es auch eine Konfiguration in der json Datei, die beschreibt, in welche Tabelle welches ausgelesene Feld soll:
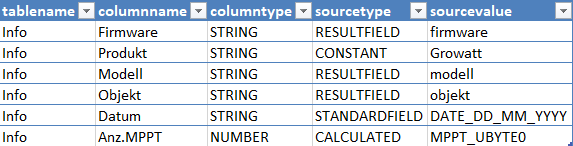
Damit wird die Struktur von Tabellen beschrieben, wo die Daten herkommen und wie diese präsentiert werden sollen.
Je nach „sourcetype“ können die eben ausgelesenen Resultfields oder Standardfelder verwendet oder sogar Berechnungen durchgeführt werden. (Standardfelder sind Felder, die z.B. die ganzen Datums- und Zeitberechnungen vorhalten)
Mit diesen Angaben kann nun der Export erfolgen. Dafür gibt es dann verschiedene „Exporter“, die die Tabellen auswerten und passend in die Zieldatenbank übertragen.
Derzeit wird nur Influx V1 und V2 unterstützt, aber es könnten theoretisch beliebige Exporter z.B. für MySql nachprogrammiert werden.
Im Konzept ist auch eine zeitliche Eingrenzung der Abfragen vorgesehen. So steuert man mittels einem „Activity“ Abschnitt für jedes Gerät, wann und wie oft das Auslesen erfolgen soll:
Code: Alles auswählen
"activity": {
"enabled": true,
"interval": 10,
"timeUnit": "SECONDS",
"startTime": "05:00:00",
"endTime": "22:00:00"
}Die ganze Konfiguration der Geräte (beliebig viele möglich) erfolgt derzeit auch über eine json Datei.
Das Ganze soll als OpenSource Projekt realisiert werden, damit sich auch viele beteiligen können und die Arbeit nicht auf einem alleine lastet. Ulrich kann bestimmt ein Lied davon singen.
Vorerst bin ich aber auf Eure Hilfe angewiesen:
Ich suche noch Tester, die bereit sind, auszuprobieren und auch mal log Dateien zurückschicken und evtl. von Ihrem Gerät die Spezifikation liefern, falls vorhanden. Derzeit hauptsächlich Geräte, die mit dem Modbus Protokoll arbeiten, aber andere gehen natürlich auch.
Voraussetzungen, damit das Programm läuft:
- installiertes Java, mindestens Version 8
- Installierte Influx Datenbank irgendwo zugänglich, ist aber kein Muss!
Bei mir läuft das Programm direkt auf einer Synology DS218+ mit einem angeschlossenen RS485 Konverters, ein Raspberry PI geht natürlich auch. Es ist kein Image, sondern ein tar File, welches eine jar und die Start- und Stop-Skripte enthält (insgesamt ca 5 MB gross)
Hier noch einmal zusammenfassend die Vorteile, die ich darin sehe:
- beliebig viele Geräte verwaltbar
- aktives Zeitfenster und individueller Auslese-Intervall für jedes Gerät
- schnelles Auslesen durch Blockweises Lesen anstatt einzelner Abfragen
- echtes Multitasking
- leichtes Anpassen der Gerätekonfiguration ohne Programmierkenntnisse
- keine Cronjobs nötig, der Java Prozess wird nur einmal gestartet
- kein grosses Image nur für den Pi, sondern ein kompaktes tar / zip für alle Endgeräte mit Java
Also was haltet ihr davon?
Viele Grüße
Schnippsche
